Table of Contents
- Introduction
- Inner join
- Left join
- Right join
- Outer join
- Indicator
- Validate parameter
- The effect of column name
- Video Tutorial
1. Introduction
In this session two sets of data will be used: Employee.csv, Dept.csv.
The employee data set contains the data regarding the employee. Such as name, job, employee number, etc. The department data set contains the data regarding the departments like department number, name, and city. These two data sets are shown in figure 1. Note that both the tables have something in common. That is the department number, which is denoted by DEPTNO.

2. Inner join
We are going to inner join using the department number column. To do this we can use the merge() function in Pandas.
First we need to pass the left data set and right data set as employee and dept. The column which we are going to apply inner join should be passed in to the on parameter. Then the type of the join should be specified using the how parameter. The code is shown below.
emp_dept = pd.merge (employee, dept, on=[‘DEPTNO’] , how= ‘inner’)
Execute the data frame. The result is shown in figure 2.It can be seen that the two tables are joined according to the department number.
Note that the records are sorted out, by default according to the given column.
Also note that, because this is inner joined, the record for the department number 50 (employee name Clara) is not present. As it was not common for the both data sets.

3. Left join
To left join the data set, simply change the how parameter to left as shown below.
emp_dept = pd.merge (employee, dept, on=[‘DEPTNO’] , how= ‘left’)
In this scenario, the records from the left data set and common records are joined together. Execute the code to display the results as shown in figure 3.

Note that now the Clara record is also present in the table after the left join. But the Dname and City column values are null because they are not available in the department data set.
4. Right join
To right join the data set, simply change the how parameter to rightas shown below.
emp_dept = pd.merge (employee, dept, on=[‘DEPTNO’] , how= ‘right’)
In this scenario, the records from the right data set and common records are joined together. Execute the code to display the results as shown in figure 4.

Note that the right data (department data) contains a record that has the DEPTNO as 40. But the left data set doesn’t contain any record related to DEPTNO 40, it’s unavailable. Hence, the values are shown as null values.
5. Outer join
In order to join the both tables such a way that all the values in left and right data sets are present, even they match or un-match, outer join can be used.
To outer join the data set, simply change the how parameter to outeras shown below.
emp_dept = pd.merge (employee, dept, on=[‘DEPTNO’] , how= ‘outer’)

6. Indicator Parameter
In order to find out the data set which the records are available from, the indicator parameter can be used. This parameter value should be set as True. Then execute.

Refer the figure 6. It can be observed that 0-5 indexed records are available at both sides, record 6 available at left only and record 7 is available at right only.
A name for the indicator column also can be set as the value of the indicator parameter as shown in figure 7. In here the indicator column is set as indicator_col.
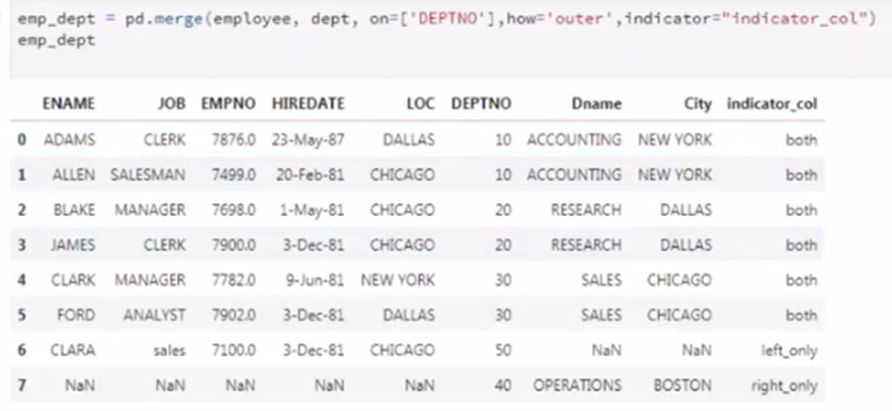
7. Validate parameter
Refer the data sets in the figure 1. Note that the department data set contains one record for DEPTNO 10 whereas in employee data set for DEPTNO 10 there are two records. Hence, when we try to join them, a problem arises because for the number 10 there are multiple matches.
We can use the validate parameter to find out if there is a problem when joining the data sets. The values can be given as: one to one, one to many.
As an example, we will put one_to_one as the value, so that it will give an error because in here we have a one to many relationships. Execute the code in figure 8. After executing we can see that it throws an error.

Then put the value as one_to_many. Now, we can get the perfect table as shown in figure 9.

8. Effect of the column name
We are joining the data sets according to a column name. Hence that column name should be present in both data sets.
Let’s assume, now employee data set has a column name as DEPTNO and department data set has a column name as DEPT_NO. If the on parameter is given as DEPTNO, it will give us an error now. Because the data sets couldn’t be joined because that the column DEPTNO is only available in employee data set.
In a situation like this, two parameters should be specified. These are left_onand right_on parameters. We need to specify the left and right column names by telling the system that we need to join considering those columns. The code is shown in figure 10.

Then execute the code as shown in figure 11. Now the data sets are joined as per our requirement.

Video Tutorial